The date is set. After successfully crossing the initial stages, you are ready for the grand finale! Now all that remains is to brush up on a few FAQs before the d-day. Following are the top 10 common questions asked in any data science interview.
 Book Free Strategy Call
Book Free Strategy Call
Upcoming Batches of Business Analytics Certification :-
| Batch | Mode | Price | To Enrol |
|---|---|---|---|
| Starts Every Week | Live Virtual Classroom | 15000 | ENROLL NOW |
1. Define Data Science
When answering this question, do not stop with the generic definition. Explain further about how you use data science on a personal and professional level. And that will help to establish your ease of usage in the domain.
Also, it is always important to make sure you steer the interview and not the other way around. One method to maintain control is by ending answers with a keyword trigger to the next question, a question for which you know the answer.
For e.g., Make sure to talk about structured and unstructured data when explaining data science Course, as that will immediately trigger to our next question in the list.
2. What is the difference between structured and unstructured data?
Start with a layman’s definition and then proceed to highlight the technical differences. This will help to showcase your comprehension skills too.
Looking forward to becoming a Data Scientist? Check out the Data Science Bootcamp Program and get certified today.
| Structured Data | Unstructured Data |
| Highly organized and formatted | No predefined format or organization |
| Quantitative | Qualitative |
| It is managed mainly by relational or SQL (Structured Query Language) databases | It is managed mainly be non-relational or NoSQL databases |
| Presents an overall view of the trends | Presents an in-depth view and understanding of the data trends |
| Examples: Names, Dates, Addresses, Credit Card details etc. | Examples: Text, Videos, Audios, Social Media usage etc. |

3. What is selection bias?
One cannot discuss data without understanding the effects of selection bias. Choosing data, groups or people without proper randomization is selection bias.
A famous example of selection bias explanation is the anecdote of Abraham Wald, the statistician who increased the survival rate of the US Aircraft in WW2. And the discussion ensuing that could be an interesting point to connect with your interviewer.
Finally, you could choose any data specific to the company you are interviewing for, and end with a technical demonstration to use statistics to approach and eliminate the selection bias. For e.g., the members of Buzzfeed used statistics to eliminate all selection bias before translating a few of their articles. And that helped them reduce a lot of unnecessary effort and resources.
4. What are Interpolation and Extrapolation?
Extrapolation is a method by which data beyond the known values are estimated.
Interpolation is a method by which data within a known set of values is estimated.
Explain the difference with a proper statistical example that will highlight your technical prowess in data science.
5. What is a Boltzmann Machine?
This is the point at which you understand that the interview is venturing deep into technical territory, and you best be fully prepared.
Boltzmann Machine is a famous Neural Network and is capable of learning representations and solve combination problems. The Boltzmann machine is a famous buzzword in the data science community.
Go into depth while explaining this core data science concept as it will showcase your strength and forte in the field.
6. What is the Law of Large Numbers?
This laws states that when you repeat an experiment for a large number of times, the end average tends to be closer to the expected outcome (true population).
An easily understandable example is the dice probability, say you roll a dice 3 times and get the following outputs:
5, 5, 6, the average is 5.33. But, when you roll the same dice for a larger number of times, the output comes closer to the expected average, 3.5.
Expand your explanation with an example from the company itself, which will help to portray your application skills.
7. What are Eigenvectors and Eigenvalues?
These are concepts that we learnt in high school math, so it would be helpful to have a quick brush up of the same before the interview.
An Eigenvector is a vector which remains unchanged even after linear transformation is applied to it.
The value of the above vector’s change in length is called the Eigenvalue.
After this brief explanation, proceed to draw a proper matrix and explain the mathematical concepts behind Eigenvectors and Eigenvalues, this will reflect your strength in basic Math too.

8. What is Logistic Regression?
Logistic Regression is an algorithm used to predict a binary outcome when a set of independent variables are given.
It can be explained with a simple example of shooting baskets in the game of basketball. The output will be a simple binary of 0 for missing the shot and 1 for getting the shot. The following scatter plot will give an idea of the result of various shots taken.
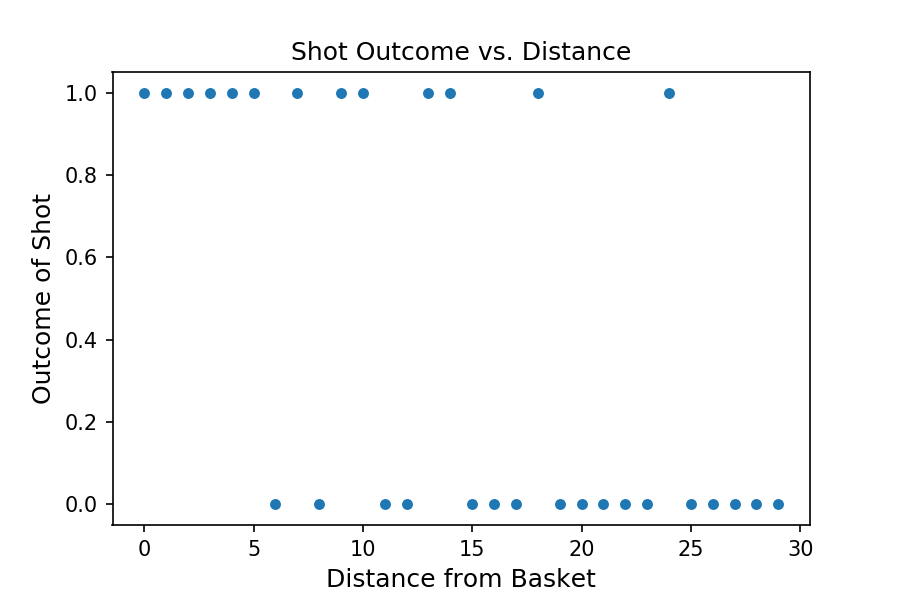
A simple real life example like this would be enough to establish your understanding on the subject.
9. Explain Gradient Descent
Gradient Descent is an algorithm that minimizes a function by iteratively moving in the steepest negative descent direction till it reaches the bottom.
The three types of gradient descent are:
- Batch gradient descent
- Stochastic gradient descent
- Mini-batch gradient descent
Follow this up with an explanation of the 3 types of descent and a simple example, that will help to clinch the deal.
10. What is A/B testing in data science?
In this method, 2 variations of the same webpage are shown to consumers, and the results are checked to see which variation produced the most conversions, i.e. customers taking action. This method is also called split testing.
Especially useful in the current times, where many websites tend to suffer from high bounce rates, i.e. customers who leave without taking action. This method helps to retain loyal customers by finding out and providing to them what they would like to view.
Complete with a real-time example and your answer is solid.

Armed with these tips, the knowledge from your data science or machine learning courses and confidence, the data science interviews will be a piece of cake! We hope you find the Best Opportunity in Data Science. All the best!
Recommended Read:
- Top 15 Best Data Science Course in Mumbai
- Top 10 Data Science Course in Pune
- Top 10 Data Science Course in Bangalore
- Top 10 Data Science Courses in Nagpur
- Top 20 Data science course in Delhi NCR
- Top 10 Data Science Course In India
Also Check this Video
E&ICT IIT Guwahati Best Data Science Program
Certified Python Business Analyst (CPBA) course is a focused 32-hours instructor-led training and certification program that equips participants to explore+analyze+solve business problems using popular analytics tools such as Python & Advanced Excel.
View Course
