Preface:
 Book Free Strategy Call
Book Free Strategy CallYou must be wondering what it takes to give a winning job interview?
When it comes to going for a job interview most of us drip in sweat at the mere thought of it. Many questions dawn on us such as what questions should I prepare for an interview? What would an interviewer ask me? What questions can I ask the interviewer concerning working profile or working conditions?
Upcoming Batches of Business Analytics Certification :-
| Batch | Mode | Price | To Enrol |
|---|---|---|---|
| Starts Every Week | Live Virtual Classroom | 15000 | ENROLL NOW |
These are some general questions that consume our minds.
In this article, I have listed the Top 30 most commonly asked Data Science interview questions and their possible answers.
With these questions, you can refine yourself to be a desirable participant to your interviewer for a Data Scientist profile.
Check out these questions.
Looking forward to becoming a Data Scientist? Check out the Data Science Bootcamp Program and get certified today.
Q-1. Tell me about yourself.
The first and foremost question that every interviewer asks is your introduction. An interviewer asks about you to get familiar with you and know how you can be an asset to his company.
Giving an introduction about ourselves is tough as many times we get stuck after saying three lines and forget to mention the highlights about our profile.
To prepare for this question, I recommend you write down important highlights about your profile that can serve as an asset to the company.
For instance, in one or two sentences give a glimpse of your personal life. Then showcase your educational qualification, your previous working experience, and give them a hint that you are a perfect fit for the profile in their company and that you will be an asset to them.
After you have written a crisp and apt introduction about yourself practice it before the mirror to build confidence in yourself.
Q-2. Can you please tell us more about your working experience?
To answer this question, I would suggest you carefully analyze your job profile and specify the details from your previous work experience that can help in your new profile. So when you answer this question be sure to emphasize or highlight those details that you’ve learned and will help you to perform in your new role.
These are some common questions that most interviewers ask to become familiar with you.
The other set of questions wherein an interviewer checks your knowledge about the subject and topics.
I have listed the most commonly asked interview questions that relate to Data Science below.
Q-3. Define Data Science in your own terms.
When an interviewer asks you to define any term in your own language, it is because he wants to know how you understand the topic rather than hearing a recitation of a bookish definition.
Defining Data Science course , in simple terms, refers to the combination of various tools, algorithms, and machine learning principles to analyze raw data that will help to make business decisions. A data scientist uses his skills and knowledge of statistics and mathematics to extract value from data. They help to interpret data and reveal what’s trending which can help businesses to produce creative products and services.
This is my understanding of Data Science but you can make your own definition.

Q-4. Why do you think Data Science is important for businesses?
To do this, you must describe how companies across all sectors are making decisions based on analyzing massive amounts of data kept in databases. Therefore, businesses can improve their decision-making and stay competitive in the market with it.
Data science allows companies of all sizes and in all kinds of industries to construct models using the gathered data.
In addition to this, you can also explain how BI tools are not sufficient now to interpret large and unstructured data, developing the need for more advanced technology to use.
Q-5. Mention any two roles and responsibilities performed by a data scientist?
The roles and responsibilities that a data scientist perform are:
- The foremost role of a data scientist is to interpret data and solve complex problems.
- Another common role performed by a data scientist is to use the extracted information to meet the business needs and help them meet their goals.
Q-6. Name some of the tools used by a data scientist.
I have listed 25 tools that are used in Data Science. You can mention at least 10-15 tools.
- R Programming
- Python Coding
- MS Excel
- Apache Hadoop
- Apache Flink
- Tableau
- TensorFlow
- BigML
- Knime
- RapidMiner
- Apache Spark
- Google Analytics
- MATLAB
- SPSS
- Julia
- Trifacta
- QlikView
- Minitab
- MongoDB
- Sap Hana
- Apache Kafka
- DataRobot
- PowerBI
- SAS (Statistical Analysis System)
- BigML (Machine Learning)
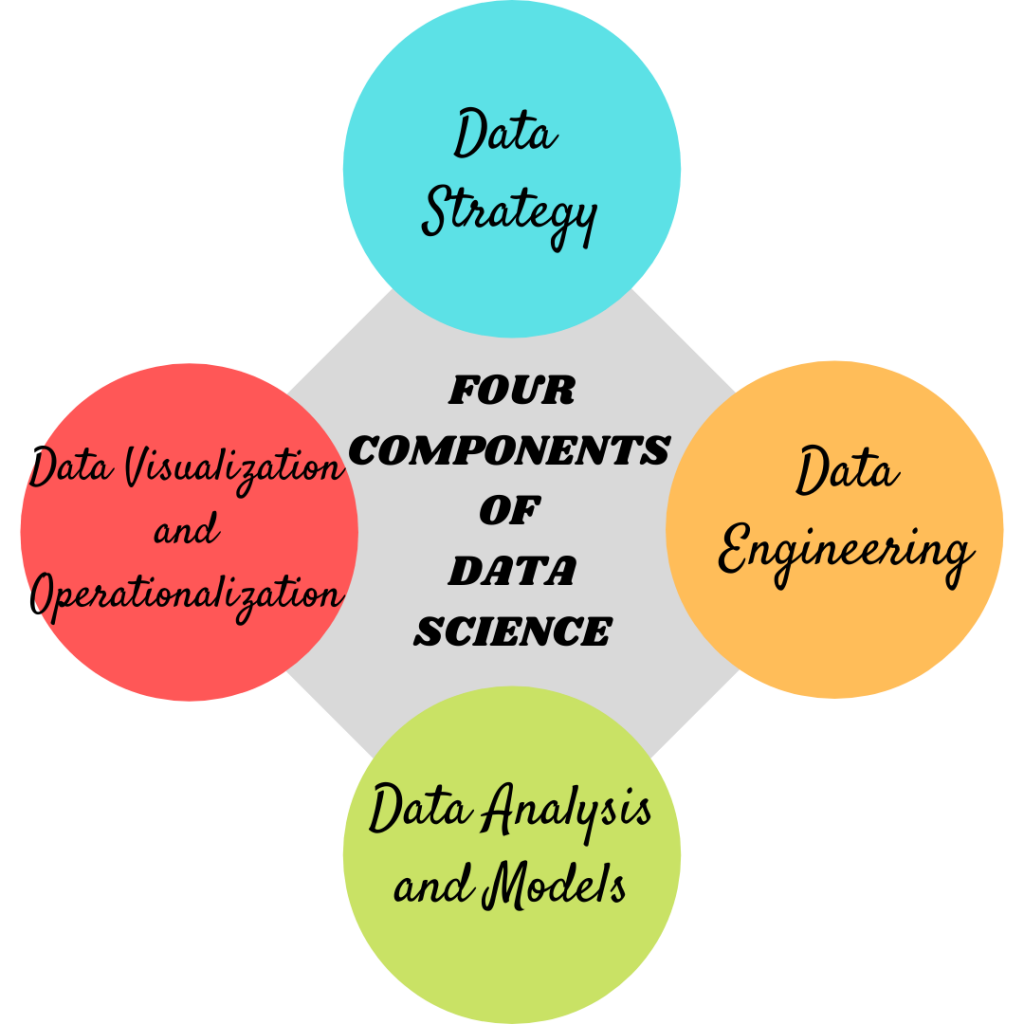
Q-7. Name four components of Data Science.
Below I have mentioned the four components of Data Science. To exhibit your knowledge about the concepts, you can also explain each concept briefly.
The four components of Data Science are:
- Data Strategy
- Data Engineering
- Data Analysis and Models
- Data Visualization and Operationalization.
Q-8. How well do you know R?
R is among the actively utilized and in high-demand languages on the market. To elaborate on your comprehension of R programming, you may provide additional information or define the language in your own words. The interviewer is astounded when a candidate explains a concept according to their own understanding instead of reciting a definition they have memorized. Therefore, I have provided a succinct definition below; however, you may supplement it with your own.
R, which was developed by Ross Ihaka and Robert Gentleman, is an open-source application. Besides, it is both a language and a tool. R is valuable for data analysis, statistics, and machine learning.
Additionally, users can apply this programming language with other languages.
Q-9. How Python Programming helps a data scientist?
The pre-built code stored in the library of Python helps a data scientist perform common tasks. This programming also helps to build on top of other works, saving the time to start from scratch. Python libraries such as NumPy, Pandas, and Matplotlib help a data scientist in the tasks of data cleaning, data visualization, and data analysis.
Q-10. How does R illustrate missing values and impossible values?
The missing values, in R, are represented by NA, a symbol that means not available.
Whereas, impossible values are represented by NaN, a symbol that means not a number.
Q-11. How much Transpose is significant in R?
Transpose, in R, is a matrix that helps to reverse rows into columns and columns into rows. It helps to easily reshape a dataset.
Q-12. How do primary and foreign keys differ from one another?
A primary key is a column or set of columns in a database table whose value is distinct for each record. Primary key values are not permitted to be undefined.
A foreign key, conversely, consists of a column or collection of columns within a table that establishes a reference to the primary key columns.
Q-13. What is your understanding of the term Normal Distribution?
Normal Distribution, or the Gaussian distribution, is a type of probability distribution that shows the symmetrical distribution of data near the mean. When a normal distribution is presented on a graph, it appears in a bell curve shape. To understand the normal distribution, Python code can also be used.

Q-14. How can one assess the Normal Distribution?
There are several methods to check the Normality of a Distribution. Some of the methods are:
- Histogram
- Kernel Density Estimation (KDE)
- Q_Q (quantile-quantile) Plot
- Skewness
- Kurtosis
Q-15. What do you understand about Random Forest?
Random Forest is one of the widely accepted machine learning algorithms classified under the supervised learning technique. The forest is built by combining multiple classifiers to bring solutions to complicated problems, thus, helping to improve the performance of a model. With a large number of forests, the risk of overfitting is avoided and it also leads to increased accuracy.
Q-16. Explain the term overfitting.
Overfitting, in simple terms, occurs when a statistical model is overfed with data. When such an event happens, the model starts training itself from the noise and inaccurate data entries. It is similar to trying to fit in an oversized cloth.
Q-17. How to avoid overfitting?
There are many ways to avoid the overfitting of statistical models. The most common ways are:
- Cross-validation
- Train with more data to help the model detect the right signals.
- By removing irrelevant features from the model.
- Overfitting can also be avoided by preventing it at an early stage. In this, one needs to measure each iteration at all levels.
- Through regularization, overfitting can be avoided. In this solution, techniques to artificially force the model to be made simpler are used.
- Ensembling is another way to avoid overfitting data.
Q-18. Define bias.
Bias is statistically defined as an incorrect estimation of a parameter. The outcomes of the expected value diverge from the estimated value under such circumstances. Bias can lead to the underestimation or overestimation of results.
Q-19. Name some of the biases that can happen during the sampling process.
Some of the biases that occur during the sampling process are:
- Selection Bias
- Self-Selection Bias
- Observer Bias
- Survivorship Bias
- Pre-screening or Advertising Bias
- Undercoverage Bias
Q-20. What measures can be taken to eliminate bias from the sampling procedure?
There exist multiple methods to eliminate bias from the sampling procedure. Some methods for preventing bias in the sampling procedure include:
- Randomization
- Systematic sampling
- Cluster Sampling
- Stratified Sampling
- Oversampling (to prevent under coverage bias)
Q-21. Contrast unsupervised learning with supervised learning.
-
The application of labels to the dataset is one of the primary distinctions between supervised and unsupervised machine learning. In contrast to unsupervised machine learning, which operates with unknown and unlabeled input, supervised machine learning utilises labelled and recognisable datasets.
-
Unsupervised machine learning lacks a feedback mechanism, which is an additional differentiation between the two methodologies.
-
In conclusion, techniques can be used to distinguish between supervised and unsupervised machine learning. For the purpose of comprehending and analysing data, supervised machine learning employs classification and regression. Unsupervised machine learning, conversely, evaluates the data through the integration of association, dimensionality reduction, and clustering.

Q-22. What do you understand about the Decision Tree Algorithm?
The Decision Tree Algorithm is a part of a supervised learning algorithm used for classification and regression problem-solving. The use of a decision tree algorithm is mainly for creating models that will help to predict class labels or values by decision-making rules.
Q-23. What do you mean by prior probability and likelihood?
Prior probability can be defined as a probability of an event that is calculated before the collection of new data. In prior probability, the probability is computed before taking evidence into account, expressing one’s belief.
The likelihood, on the other hand, is the probability of attaining results for data given a particular parameter.
Q-24. Name some of the libraries in Python used for Data Science.
The libraries used for Data Science in Python are:
- Pandas
- TensorFlow
- NumPy
- SciPy
- Keras
- BeautifulSoup
- Scrapy
- PyTorch
- SciKit-Learn
- Matplotlib
Q-25. Define Backpropagation.
Backpropagation is a short form for backward propagation of errors and is also known as backprop or BP. Backpropagation is an algorithm that works to tune the weights of a neural net using the technique of delta rule or gradient descent. By reducing the error rates, backpropagation helps to increase the generalization of the model.
Q-26. Explain Deep Learning.
Machine Learning is the umbrella term for Deep Learning. A few lines of code are utilized to generate a predictive and problem-solving model through this system. A neural network that emulates the architecture and operation of the human brain. Deep Learning systems can outperform human brains in terms of intelligence thanks to their distinctive combination of speed and precision.
Q-27. Name some of the Deep Learning Frameworks.
Some of the most commonly and extensively used Deep Learning frameworks are:
- TensorFlow
- PyTorch
- Keras
- MXNet
- Sonnet
- ONNX
- Chainer
- Gluon
- Swift for TensorFlow
- DL4J
Q-28. Name some of the Machine Learning Algorithms with Python and R.
Some of the most commonly used Machine Learning Algorithms with Python and R are:
- Random Forest
- Linear Regression
- Logistic Regression
- KNN
- Naive Bayes
- SVM
- Decision Tree
- K-Means
- Gradient Boosting algorithms
- Dimensionality Reduction Algorithms
Q-29. Define Collaborative Filtering.
Collaborative Filtering is a technique that is used to filter out items using the interactions and collection of data from other users.
Q-30. Explain recommender systems.
Recommender systems are data science courses that utilise a variety of factors to forecast and suggest items that a user might find interesting. These systems possess the capability to predict which product a user is most likely to be intrigued in or potentially purchase of by analysing their burning history. Prominent organisations that implement recommender systems include Amazon and Netflix.
Conclusion:

Please keep in mind, as you utilise these interview preparation questions, that Data Science encompasses a vast array of subjects. Thus, the content presented in this blog represents only a fraction of the extensive array of subjects. It is strongly advised that you supplement the definitions with your own interpretations and comprehension of the concepts, as opposed to simply committing definitions to memory. Understand the term, concept, or subject matter you are perusing before providing your own interpretation. You will be capable of maintaining comprehension and knowledge of the concept indefinitely in this manner.
Additionally, in order to convey to the employer your level of professionalism, it is advisable to consistently wear formal attire to interviews.
Further to the inquiries enumerated above, I suggest perusing the following blogs, which delve into the practical applications of data science in present circumstances.
Recommended Read:
- Top 15 Best Data Science Course in Mumbai
- Top 10 Data Science Course in Pune
- Top 10 Data Science Course in Bangalore
- Top 10 Data Science Courses in Nagpur
- Top 20 Data science course in Delhi NCR
- Top 10 Data Science Course In India
Also Check this Video
Wishing you good luck!
FAQs:
Ques 1. Where can I learn Data Science?
Ans: I heartily recommend checking out Henry Harvin Education for learning Data Science. The institute stands at the First Position in the List of Top 5 Upskilling Courses in India to Make You Job Ready by prestigious publications— India Today and Tribune India.
- Data Science with Python Course
- Data Science with R Course
Ques 2. What are some roles I can take after completing a Data Science course?
ANS: The Top role that you can take after completing a Data Science course are:
a. Data Analyst
b. Data Scientist
c. Data Engineer
d. Machine Learning Engineer
e. Quantitative Analyst
f. Business Analyst
g. Operations Analyst
h. Statistician
i. Data Administrator
Ques 3. What are the Top Programming Languages for Data Scientists?
Ans: The Top Programming Languages for Data Scientists are:
i. R
ii. Python
iii. SAS
iv. TensorFlow
v. SQL
vi. JULIA
vii. SCALA
Ques 4. What are the must-have skills required for becoming a Data Scientist?
Ans: The four major skills required for becoming a Data Scientist are:
1. Mathematics and Statistics: One of the primary requirements for becoming a Data Scientist is a background in mathematics and statistics. Only choose Data Science if you are truly passionate about these subjects. The reason is, that a Data Scientist’s primary responsibility is to aid organizations in reaching their objectives through the analysis of data and statistics.
2. Domain knowledge and soft skills: Only having an interest in mathematics and statistics is not enough, a Data Scientist is also required to have a thorough knowledge of the domain and acquire soft skills.
3. Programming and Database: It is another prerequisite that a Data Scientist should acquire.
4. Communication and visualization: Because a Data Scientist does not work alone and has to work with a team, he/she needs to have good communication skills.
Ques 5. What are some companies that hire Data Scientists for higher salaries?
Ans: The companies known for hiring data scientists for higher wages are:
a. Microsoft
b. Crayon Data
c. Intel
d. Lyft
e. Slack
f. Uber
g. Accenture
h. Oracle
i. Uber
j. Snap Inc
Ready to Start Your Learning Journey?
Join thousands of learners and build your future with expert-led courses and 100% practical training.
- Expert GuidanceLearn from industry experts
- Trusted & RecognizedTop-rated by learners
- Flexible LearningOnline & offline options
- Placement SupportCareer support & more
E&ICT IIT Guwahati Best Data Science Program
Certified Python Business Analyst (CPBA) course is a focused 32-hours instructor-led training and certification program that equips participants to explore+analyze+solve business problems using popular analytics tools such as Python & Advanced Excel.
View Course
