Fraud that involves cell phones, insurance claims, income tax return claims, MasterCard transactions, and many more demonstrate significant problems for the government, businesses, and other organizations. Data and Information analysis techniques are used to identify fraudulent behavior and, thus, prohibit any kind of abnormal activity by the user.
These methods exist within the areas of Data Discovery in Databases (KDD), data processing, Machine Learning, and Statistics. They offer applicable and successful solutions in several areas of electronic fraud crimes.
 Book Free Strategy Call
Book Free Strategy CallIn general, the first reason to use data analytics techniques is to tackle fraud since many control systems have serious weaknesses. To monitor systems against fraudulent activities – businesses, entities, and organizations believe in specialized data analytics techniques like data mining, data matching, and sounds like function, Regression analysis, Clustering analysis, and Gap.
Upcoming Batches of Business Analytics Certification :-
| Batch | Mode | Price | To Enrol |
|---|---|---|---|
| Starts Every Week | Live Virtual Classroom | 15000 | ENROLL NOW |
We, at Henry Harvin provide various Data Science Courses and Data Analytics Courses designed as per the latest Data Analyst techniques and methods. Our course content is aligned with the upcoming requirements of Data analytics in various sectors and industries. You can simply choose the best Data Analytics Training Program to upskill your data science skills and move forward in your career.
A student or working professional from any background can enroll in a suitable Data Science Course from Henry Harvin at his convenience. you can simply opt for the online learning option as per your schedule. Moreover, Henry Harvin in collaboration with E&ICT Academy, and IIT Guwahati, provides various online courses in disciplines like Data Science, Data Analytics, Digital Marketing, HR analytics, and more.
Here is the list of Data Science Courses by E&ICT Academy, IIT Guwahati, such as:
- Basic Certification Course in Data Science with Python by E&ICT Academy, IIT Guwahati
After successful completion of the course, candidates avail the benefits of achieving a Dual Certificate of Data Science Course from Henry Harvin and E&ICT Academy, IIT Guwahati.
Data Analytics Techniques for Extortion Detection
With the progression of technology, tools, and strategies in the field of Data Science. We have various updated data analytics strategies commonly used for fraud detection:
- Anomaly Discovery: This method distinguishes unordinary designs or exceptions in data that may demonstrate false behavior.
- Machine Learning Algorithms: Administered machine learning algorithms such as logistic relapse, decision trees, random woodlands, support vector machines (SVM), and neural networks can be prepared on authentic data to classify transactions as false or non-fraudulent based on features such as transaction amount, frequency, location, etc.
- Social Network Analysis (SNA): SNA analyzes the connections between entities (e.g., customers, accounts) to identify patterns demonstrative of fraud activities.
- Predictive Modeling: Predictive modeling involves building predictive models utilizing historical information to forecast the probability of future false exercises. Methods such as relapse examination, time arrangement examination, and survival examination can be applied.
- Text Mining and Common Dialect Handling (NLP): Content mining and NLP procedures can be utilized to analyze unstructured information such as content in emails, chat logs, or social media to recognize suspicious dialect or communication patterns related to fraud.
- Fraud Scorecards: Fraud scorecards are statistical models that assign a score to each exchange or entity based on various risk variables. These scores offer assistance in prioritizing examinations or flagging suspicious exercises for advance review.
- Graph Analytics: Graph analytics strategies are utilized to analyze complex relationships and conditions between entities in a network. This approach can offer assistance reveal covered-up connections or patterns demonstrative of fraudulent behavior.
- Behavioral Analytics: Behavioral analytics includes checking and analyzing client behavior over time to build up typical designs and distinguish deviations that may show extortion. This approach is especially valuable for identifying insider threats or account takeover fraud.
- Pattern Recognition: Pattern recognition techniques include identifying recurring patterns or marks of known fraudulent movement within data. This may include rule-based frameworks, pattern-matching algorithms, or fuzzy logic.
- Geospatial Analysis: Geospatial analysis includes analyzing geographic information such as IP addresses, GPS facilitates, or charging addresses to recognize suspicious patterns or irregularities based on location.
- Cross-Channel Investigation: Cross-channel investigation includes coordination data from different sources or channels (e.g., online transactions, ATM withdrawals, call center interactions) to identify irregularities or inconsistencies that may show fraudulent activity.
- Continuous Monitoring and Real-Time Analytics: Persistent monitoring and real-time analytics empower organizations to identify and react to fraudulent movement as it occurs, or maybe then depending solely on clump handling or periodic reviews.
These techniques can be utilized separately or in combination to build vigorous fraud detection frameworks tailored to particular industries and use cases. Furthermore, the effectiveness of these methods frequently moves forward over time as models are persistently prepared and refined with modern information and insights from fraud investigations.

How Data Analytics Can Assist in Fraud Detection
Fraud takes place in many different forms, and it affects virtually every industry, although not in equal measure. The sectors that deal with it use various techniques to get to the bottom of when and why fraud happens. They often use data analytics to help.
A primary advantage of knowledge analytics tools is that they will handle massive quantities of data directly. These solutions typically learn what’s normal within a set of data and the way to identify anomalies.
Data analytics technology doesn’t replace the need for humans, who scrutinize the content and findings, but it can track trends and possible problems substantially faster than people could without help.
Looking forward to becoming a Data Scientist? Check out the Data Science Course and get certified today.
Using Data Analytics to Find Tax Fraud

Many people view tax time as at least mildly stressful. They’re worried about making honest mistakes, such as math errors, that could lead to them getting audited. But, other individuals engage in illegal activities to wrongfully receive refunds.
If you want an idea of the scale of refunds issued to U.S. citizens by the Internal Revenue Service (IRS), consider that in the fiscal year 2018, the organization distributed refund amounts totaling nearly $464 billion.
The IRS says tax noncompliance, which includes refund fraud, increases the tax burden on taxpayers who want to stay above board.
The entity depends on predictive analytics to assess the reliability of individual tax returns. For example, if a person has filed taxes for the past three decades, the system could look at the characteristics of all those returns and determine whether they align with the most recent paperwork from a taxpayer.
The IRS system also uses clustering to find elements that may be common to numerous returns. Widespread data breaches have made it easier for fraudsters to obtain real information and use it for tax fraud.
That shift meant the IRS had to depend on advanced measures to discover incidents and data analytics fit the entity’s needs.
Cracking Down on Pharmaceutical Fraud with Data Analytics

Fraud in the medical sector can happen when a provider prescribes a drug or other treatment to someone who doesn’t have a genuine medical need for it if a drug company charges inflated prices for medicine, and more.
Often, this kind of fraud extends to the federal government, especially when patients are Medicare participants.
If someone has evidence that a company or individual defrauded the government in some way, such as by charging for services never performed, overcharging, or billing for services or products never received, a whistleblower may make a filing under the False Claims Act.
When whistleblowers sue on behalf of the government and get a successful result, they receive 15 to 30% of the money recovered by the government.
In one recent incident involving alleged Medicare fraud spanning multiple states, a drug manufacturer had to pay $2.2 million to the state of Washington after it reportedly purposely delayed the Food and Drug Administration from approving generic versions of the drug so the pharmaceutical company could remain in control of its pricing.
Data analytics could help in similar cases by examining the approval timelines for similar generic drugs and contrasting them with a medication awaiting approval.
If the process seems unusually long, investigators might realize it’s time to take a closer look at what’s causing the slowdowns.
Moreover, machine learning assists in detecting cases of pharmacy refill fraud, such as when a pharmacist refills a prescription before a patient requests it. Applying algorithms to regions, states, or individual pharmacies to assess for cases of fraud enables noticing the outliers.
Data Science Contribution to Fraud Detection in Various Applications
Data science techniques can be applied across various industries and domains to detect and prevent fraudulent activities. Here’s how Data Science can be used for fraud detection in different applications:
-
Finance and Banking
-
-
- Credit Card fraud detection: Data Science techniques such as machine learning classification algorithms can analyze transaction data in real-time to identify unusual patterns.
- Loan Application Fraud Detection: Data science models can predict the likelihood of fraudulent loan applications in support of the pattern associated with previous fraud cases.
-
-
Insurance
-
-
- Insurance claims fraud detection: Data science skills can analyze historical claims data to identify fraudulent patterns.
- Health insurance fraud detection: Data science models can identify anomalies and inconsistencies that may indicate fraudulent billing practices or unnecessary medical procedures.
-
-
E-commerce and Retail
-
-
- Payment Fraud detection: Data science techniques can analyze transaction data, including payment methods, transaction amounts, shipping addresses, and user behavior.
- Return Fraud Detection: data science models can identify patterns indicative of return fraud, such as excessive returns, returning stolen merchandise, or abusing return policies.
-
-
Healthcare
-
-
- Medicare and Medicaid fraud detection: Data science techniques can flag suspicious claims for investigation by regulatory authorities.
-
-
Telecommunications
-
- Subscription fraud detection: Data science techniques can analyze customer usage patterns, call detail records, and billing data to detect suspicious activities such as subscription fraud.
- Call and text message fraud detection: By analyzing communication patterns, call durations, and network traffic data, data science models can identify fraudulent activities such as premium rate fraud, toll fraud, or SMS spamming.
Stopping Fraudulent Retail Returns
Some stores don’t limit the number of returns a shopper can do in a particular period, such as a year.
Although that approach often increases the peace of mind for people who are worried about buying something that soon breaks due to faulty construction, other consumers have taken advantage of the system and used it to scam retailers.
Merchandise returns comprise billions of dollars every year for retailers, and a substantial percentage of them could be fraudulent.
Retailers including Best Buy, Amazon, and L.L. Bean have started using data analytics to uncover cases where a consumer might be wrongfully benefiting from an extremely liberal return policy.
However, retailers must proceed with caution when using technology in this way. If return policies become too restrictive, they could frustrate customers who have shopped with a brand for decades.
Retailers, then, must weigh the pros and cons of digging into data to identify potential return fraud and decide whether pursuing problematic cases is worthwhile considering a customer’s lifetime value.
Managing Credit Card and Bank Fraud
If your bank has contacted you recently to inquire about a suspicious charge, data analytics may have triggered that communication. Financial institutions increasingly rely on data analytics to reduce fraud.
More specifically, machine learning and predictive analytics platforms give notifications of transactions that stray from the norm. It’s then possible to curb fraud before it becomes extensive and damages a banking brand.
A 2018 report from Rippleshot about card fraud found detecting fraudulent accounts faster and reducing fraud’s impact were top goals cited by financial institutions.
The research also showed that certain types of fraud are especially time-consuming to resolve. For example, account takeover fraud, whereby an entity wrongfully assumes control of someone else’s account, has a 16-hour resolution time on average.
Well-trained data analytics platforms can look for probable issues 24/7, which makes them ideal for spotting illegal activity in different time zones. Moreover, data analysis allows for prompt responses to suspected wrongdoing, limiting the problems caused by a fraudster.
Effective Ways to Minimize Fraud-Based Activities
The coverage here shows that data analytics and similar technologies are ideal for helping organizations cut down on fraud. You may have heard of other examples, too, and indeed, should expect more companies and industries to depend on data analytics for this purpose in the coming years.
Techniques Used for Fraud Detection Fall Under Two Primary Classes: Statistical Techniques and AI.

Statistical Techniques
Examples of statistical data analysis techniques are:
- Data pre-processing techniques for detection, validation, error correction, and filling up of missing or incorrect data.
- Calculation of varied statistical parameters like averages, quintiles, performance metrics, probability distributions, and so on. For instance, the averages may include an average number of calls per month, the average length of calls, and the average delays in bill payments.
- Models and probability distributions of varied business activities either in terms of varied parameters or probability distributions.
- Computing user profiles.
- Time-series analysis of time-dependent data.
- Clustering and classification to seek out patterns and associations among groups of knowledge.
- Data matching Data matching is employed to match two sets of collected data. The process is often performed by supported algorithms or programmed loops. Trying to match sets of knowledge against one another or comparing complex data types. Data matching is employed to get rid of duplicate records and identify links between two data sets for marketing, security, or other uses.
- Sounds like Functions are employed to seek out values that sound similar. Phonetic similarity is a method to locate possible duplicate values, or inconsistent spelling in manually entered data. The ‘sounds like’ function converts the comparison strings to four-character American Soundex codes, which are supported by the primary letter, and therefore the first three consonants after the primary letter, in each string.
- Regression analysis allows you to look at the connection between two or more variables of interest. Regression analysis estimates relationships between independent variables and a variable. This method is often wont to help understand and identify relationships among variables and predict actual results.
- Gap analysis is employed to work out whether business requirements are being met, if not, what are the steps that ought to be taken to satisfy successfully.
- Matching algorithms detect anomalies in the behavior of transactions or users as compared to previously known models and profiles. Techniques also are needed to eliminate false alarms, estimate risks, and predict the way forward for current transactions or users.
Artificial Intelligence Techniques
Fraud detection is a knowledge-in-depth activity.
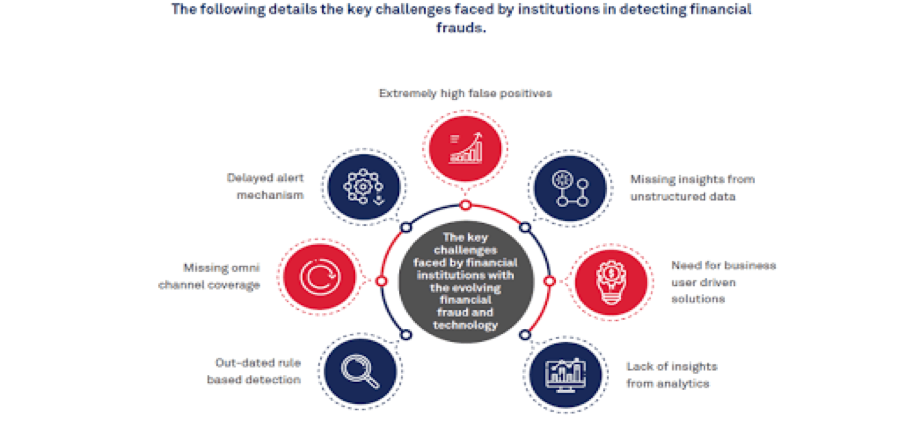
The main Artificial intelligence techniques used for fraud detection include:
- Data processing to cluster, classify, and segment the info and automatically find associations and rules within the data which will signify interesting patterns, including those associated with fraud.
- Smart systems encode expertise for detecting fraud in the form of rules.
- Pattern recognition detects approximate classes, clusters, or patterns of suspicious behavior either automatically or to match given inputs.
- ML techniques to automatically identify characteristics of fraud.
- Neural nets independently generate classification, clustering, generalization, and forecasting which will then be compared against conclusions raised in internal audits or formal financial documents like 10-Q.
Other techniques like link analysis, Bayesian networks, decision theory, and sequence matching also are used for fraud detection. A new and novel technique called the System Properties approach has also been employed wherever rank data is out there.
Statistical analysis of research data is the most comprehensive method for determining if data fraud exists. As defined by the Office of Research Integrity (ORI) data fraud includes fabrication, falsification, and plagiarism.
The statistical work was performed by Drs. Mark S. Kaiser and Alicia L. Carriquiry of Iowa State University and Dr. Gordon M Harrington of the University of Northern Iowa, where they showed that data thought to be fabricated [HI data] was real, while another set of knowledge [Hansen data] was reported to the statisticians as being fabricated was falsified and plagiarized from the HI data set.
Machine Learning and Data Mining

Old data analysis techniques were oriented toward extracting quantitative and statistical data characteristics. These techniques facilitate useful data interpretations and may help to urge better insights into the processes behind the info.
Although normal data analysis techniques can indirectly lead us to knowledge, it’s still created by human analysts.
To go beyond, a knowledge analysis system has to be equipped with a considerable amount of background, and be ready to perform reasoning tasks involving that knowledge and therefore the data provided. In an effort to satisfy this goal, researchers have turned to ideas from the machine learning field.
This is a natural source of ideas since the machine learning task is often described as turning background and examples (input) into knowledge (output).
If data processing leads to discovering meaningful patterns, data turns into information. Information or patterns that are novel, valid, and potentially useful aren’t merely information, but knowledge.
One speaks of discovering knowledge, before hidden within the huge amount of knowledge, but now revealed.
The machine learning and AI solutions could also be classified into two categories: ‘supervised’ and ‘unsupervised’ learning.
These methods seek accounts, customers, suppliers, etc. that behave ‘unusually’ to output suspicion scores, rules, or visual anomalies, counting on the tactic.
Whether supervised or unsupervised methods are used, note that the output gives us only a sign of fraud likelihood. No stand-alone statistical analysis can assure that a specific object may be a fraudulent one, but they will identify them with very high degrees of accuracy.
Supervised Learning
In supervised learning, all records will be randomly sampled and manually classified as “fraudulent” or “non-fraudulent”. Relatively rare events such as fraud may have to be oversampled to urge a sufficiently large sample size.
These manually classified records will then not train supervised machine learning algorithms. After using this training data to build a model, the algorithm should be ready to classify the new record as fraud or non-fraud.
It has extensively explored supervised neural networks, fuzzy neural networks, and combinations of neural networks and rules, and used them to detect fraud and budget fraud in the telephone network.
Bayesian learning neural network is implemented for MasterCard fraud detection, telecommunications fraud, auto claim fraud detection, and medical insurance fraud.
Hybrid knowledge/statistical-based systems, where expert knowledge is integrated with statistical power, use a series of knowledge-mining techniques to detect cellular clone fraud. Specifically, a rule-learning program to uncover indicators of fraudulent behavior from an outsized database of customer transactions is implemented.
Cahill et al. (2000) designed a fraud signature, and supported data of fraudulent calls, to detect telecommunications fraud. For scoring an involved fraud its probability under the account signature is compared to its probability under a fraud signature, post which it is updated sequentially, enabling event-driven fraud detection.
Link analysis comprehends a different approach. It relates known fraudsters to other individuals, using social network methods and record linkage.
This type of detection is merely ready to detect frauds almost like those which have occurred previously and been classified by a person. To detect a unique sort of fraud may require the utilization of an unsupervised machine learning algorithm.
Unsupervised Learning

Unsupervised methods don’t make use of tagged records.
Some important research on unsupervised learning about fraud detection should be mentioned. For example, Bolton and Hand apply Peer Group Analysis and Break Point Analysis to the spending behavior of credit card accounts.
Peer-to-peer analysis can detect individual objects that begin to behave in a different manner than before. Another tool developed by Bolton and Hand for pattern fraud detection is “breakpoint analysis.”
Unlike Maverick analysis, breakpoint analysis operates at the account level. Breakpoints are observations in which abnormal behavior of a particular account is observed. Both of these tools are suitable for consumer behavior in MasterCard accounts.
Last but not least, the integration of the data analysis process in the fraud detection system is essential for the scientific and technological development of all companies, along with a series of benefits and limitations as follows.
(a) Benefits
• get immediate answers, to a series of questions regarding fraud issues;
• Automatic data collection (predetermined flow);
• total and fast access to all data, through data indexing software (a way of sorting several records on multiple fields.);
• eliminates double records, and errors, improving the quality of data;
• High productivity vs. manual work;
• operating with incomplete and inaccurate data;
• creating a positive yield and fast return on investment;
• An increased rate for fraud detection;
• Quick detection and recovery of consequences of fraud activity;
• Creation of statistical analysis with a high degree of accuracy;
• reducing fraudulent claims;
• increase the quality of analytical products.
(b) Limitations
• Just like other labor-saving tools, fraud prevention, and detection software do not come cheap;
• A large part of data is not introduced in databases, and not all text files are included in the final reports;
• The utilization of analytical tools doesn’t save time, just optimize it. Further research/analysis by utilizing the time saved that is saved;
• A human resource is always needed, regardless of the software complexity;
Efficient anti-fraud systems involve high costs; therefore, many economic entities only like to create classic control structures.
• It is recommended that a team of experts with different experiences conduct anti-fraud activities based on hardware and software solutions and coordinate to cover various areas of activity;
• The lack of an audit plan is fragile, and for security reasons, access to information must be controlled in both internal and external ways;
• Due to the complexity of the analysis and research, the final product may be difficult to absorb, so it is recommended to use descriptive parts (explanations of tables, graphs, values, metadata, etc.).
Conclusion
The intention is to encourage antifraud managers to use proactive data detection techniques to improve fraud prevention and detection.
No toolkit can help you to start business fraud detection, is not recommended to spend too much time selecting the perfect option. Just start fighting with the fraud, use paid or unpaid software, a combination of statistical, data visualization, data mining, and filtering tools.
The process of data analysis as a tool for preventing and detecting fraud can be used successfully in any field, especially in those where databases are, or, may be easily converted into electronic format.
For fiscal, banking, insurance, and medical fraud existence of a structure is a sine qua non for the survival of business in the current exacerbation of fraud, financial constraints, and fierce competition.
Although the software is not cheap, as we have previously mentioned above, there is the possibility to maximize the benefits offered by the Office package (Excel, Access) or Active Data for Excel/Office.
Creating a system to detect and prevent fraud involves certain steps, which can be done gradually, depending on the priorities and the complexity of the system, as further presented related to hardware components:
• Determine the intention to prevent and detect fraud
• Create a special company/organization for this purpose;
• Create an IT infrastructure capable of converting internal and external data into a virtual domain;
• Ensure the process of creating and storing data in electronic format;
• Implement monitoring system data to detect violations in real-time when possible to avoid damage. The system should contain many templates (predefined models) for fraud detection.
• As an architecture, it is recommended to pre-define some parts first so that certain modules can be customized according to customer needs.
• Create a recovery system;
• Carry out comprehensive data analysis (nuclear together with most detection methods: statistics, relationships, etc.);
• Create a system that can generate intermediate and final reports based on the recipient’s requirements.
Recommended Reads:
- Top 15 Best Data Science Courses in Mumbai
- Top 10 Data Science Courses in Pune
- Top 10 Data Science Courses in Bangalore
- Top 10 Data Science Courses in Nagpur
- Top 20 Data Science courses in Delhi NCR
- Top 10 Data Science Courses in India
Also, Check this Video
E&ICT IIT Guwahati Best Data Science Program
Certified Python Business Analyst (CPBA) course is a focused 32-hours instructor-led training and certification program that equips participants to explore+analyze+solve business problems using popular analytics tools such as Python & Advanced Excel.
View Course
