
Table of Contents
Get to Know about Machine Learning Embeddings
Machine learning or Machine Learning embedding has become one of the hottest topics in recent years. It has emerged as one of the most powerful tools in Data Science. We hardly listen to the term in our daily life and one needs to gain detailed information regarding the basics and its workings. Hence, I will provide you with the information to understand Machine Learning Embeddings. So, delve into Machine Learning Embeddings with an understandable approach.

What is Machine Learning exactly?

ML is a branch of Artificial intelligence. Machine Learning allows software applications to come to more accurate outcomes. It is a way of writing Computer programs. Notably, embeddings allow computers to learn without the need of explicitly programmed. And in simple words it allows machines to learn from their experiences without the need for coding. Thus, it turns raw data into information that is meaningful in applications. Machine Learning’s other name is Predictive Analysis.
Some of the popular uses of Machine Learning are Malware threat detection, Spam filtering, Fraud Detection, Business Process Automation, Predictive Maintenance, etc. The most common usage is Search Engines.
What to know about Machine Learning Embeddings?
Machine Learning Embedding is a comparatively low-dimensional space into which you can translate high-dimensional vectors. Data Scientists use Machine Learning Embedding and it dramatically changes the system’s functioning. And, Embeddings are one of the most versatile tools in every ML Engineer’s toolkit. And, Machine Learning Embedding’s efficiency depends on a thorough understanding of what they are. Explicitly, one should not use it blindly without having a fair idea. Therefore, you must know how to operationalize machine learning embeddings in real-life world systems.
Understanding What’s an Embedding
In order to understand embeddings we need to understand first the basic requirements of a machine learning model. It is clear, most Machine learning algorithms can take input from low-dimensional numerical data only.
Actually, Embedding is the conversion of high-dimensional data into low- dimensional data. In this case, the data is converted into the form of a vector in such a way that the two are semantically similar. To clarify embeddings are dense numerical representations of real-world objects and relationships, expressed as a vector. Equally important is to understand an embedding did not capture all information contained in the original data. This is because it is a low-dimensional representation of high-dimensional data. Hence, it is a low-dimensional space.
How Machine Learning Embedding will change your approach to things: Its Basic Purpose
Machine Learning Embedding will help to reduce the number of data dimensions while preserving important internal relationships within the data. For instance, a world map provides relative positions of terrains and oceans. Moreover, Deep Neural Network models can be developed to generate embeddings and then used to build another embedding for a different set of data.
Basic Purpose Of Machine Learning Embeddings
- Identifying the embedding space’s nearest neighbors. This will allow the provision of suggestions based on the user’s interests or cluster classifications.
- Finding the relationships between categories and visualizing the concepts.
- Machine Learning Embeddings are input in the Machine Learning Model for the purpose of performing supervised tasks.
How are Machine Learning Embeddings Built?
In order to create an embedding, you must first set up a supervised machine-learning problem. As a result, training that mode, encodes categories into embedding vectors. As an example, we can build a model that predicts the next movie that a user will watch based on what they are using now. An embedding model will change the input into a vector. And that vector will be referred to predict the next movie. Emphatically, this makes a great representation that can be used for personalization. That means although we are solving a supervised problem yet the actual creation of embeddings is an unsupervised process.
Defining a Supervised Problem or a Surrogate Problem is an art, and thus dramatically affects the behavior of the embeddings. For example, YouTube are using “predict the next video and how long they are going to watch it” as a surrogate problem. And this is giving them far better results than earlier.
Things you can build with Machine Learning Embeddings
- To build all kinds of search, e.g. Text search, image search, music search, etc.
- Chatbots and question-answer systems
- Recommendation Systems( e.g. movie recommendations on Netflix)
- Data Preprocessing i.e. preparing data to be used in a machine-learning model
- Detecting problems when ML models go stale
- One-shot learning/zero-shot learning i.e. machine learning models that require almost no training data.
- “Fuzzy matching” and detection of Typo.
- Fraud Detection/Outlier Detection etc
Embeddings usage in Real World
Embedding usage started in research labs and quickly gained importance. Henceforth, Machine Learning Embeddings found their place in Production Machine Learning Systems across various fields including Natural language Processing, recommender systems, and computer vision.
1. Recommender System
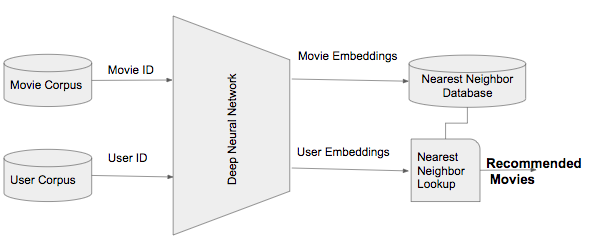
The recommender system handles a large volume of information. It works by filtering the most important information based on the data provided. And this data is either provided by the user or based on other factors that determine the user’s interests. Thus it finds out the match between the user and the item. And imputes the similarities between users and items for recommendation. Actually, it predicts the preferences and ratings of users for a variety of products/entities.
Let’s see how the recommender Machine Learning helps.
The recommender system helps users in finding items of their interest. It provides personalized content. Moreover, it helps item providers in delivering their items to the right user. This system identifies products that are most relevant to users. Hence, it improves user engagement.
2. Semantic Search
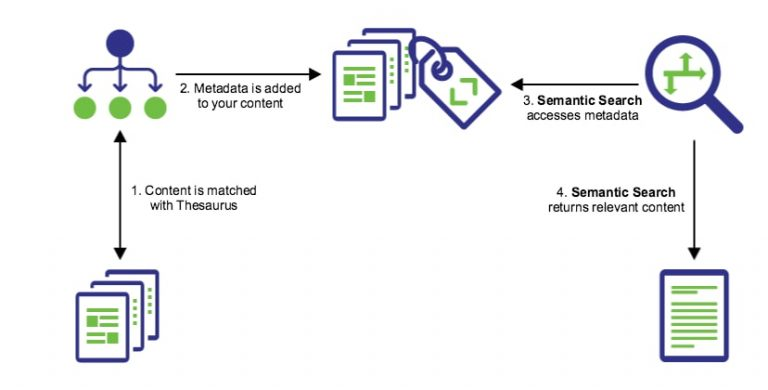
This system uses small vectors to represent items. Users want search bars to be smarter than regular expressions. Nowadays, people expect a search bar should understand the intent and context of a query. And not just look at words, be it a blog, Google search bar, or a customer support page.
A Semantic search system is divided into two parts. One part is an encoding pipeline that builds indices and the other is a search pipeline. This search pipeline allows users to use indices to search for items. Search engines are built around the term frequency-inverse document frequency (TF-IDF), which creates embedding from the text. Hence, this kind of semantic search works by finding a document embedding closest to the query embedding, using the nearest neighbor.
Nowadays, semantic search is using more sophisticated embeddings like BERT. For example, Google also uses BERT on a large percentage of queries.
3. Computer Vision

Machine Learning Embedding in Computer Vision is a way to translate between different contexts. For example in order to train a self-driving car, you can transform the image into an embedding. Thus, transform learning is generated. We can train the driving model by using embedding and not feeding it with tons of expensive real-world images. Tesla is using this type of embedding at present.
Basically, it transforms the user’s text and image into an embedding in the latent space. Image-> Embedding, Text-> Embedding, Embedding->Text, Image->Text. Thus, using this transformation, we can translate text to image and visa-versa by using intermediate representation.
List of Common Machine Learning Embedding Models
Machine Learning Embeddings are a type of neural network that uses deep learning techniques to create models that can transform raw input into meaningful output.
1. Principal Component Analysis(PCA)
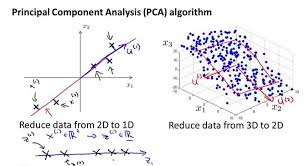
PCA is one of the methods of creating embeddings. This Machine Learning Embedding Model reduces the dimensionality of an entity by compressing variables into a smaller subset. Thus, it allows the model to behave more effectively. But this model makes variables more difficult to interpret and generally leads to loss of information. One popular implementation of the PCA technique is SVD.
Singular Value Decomposition (SVD) is a dimensionality technique. SVD uses matrix factorization to reduce the quantity of data from N-dimensions- K-dimensions.
As an illustration, let’s represent a user’s video ratings as a matrix of size(Number of users) x (Number of items). And where the value of each cell is the rating that a user gave that item. First, of all, we pick a number, k which is our embedding vector size, and use SVD to turn it into two matrices. One is ( Number of users) x k and the other is k x (Number of items). If we multiply a user vector by an item vector we will get our predicted user rating. Next, if we multiply both matrices we would get the original matrix but densely filled with all our predicted ratings. Thus we get to know that two items that have similar vectors would result in a similar rating from the same user. As a result, we end up creating user and item embeddings.
2. Word to Vector Model
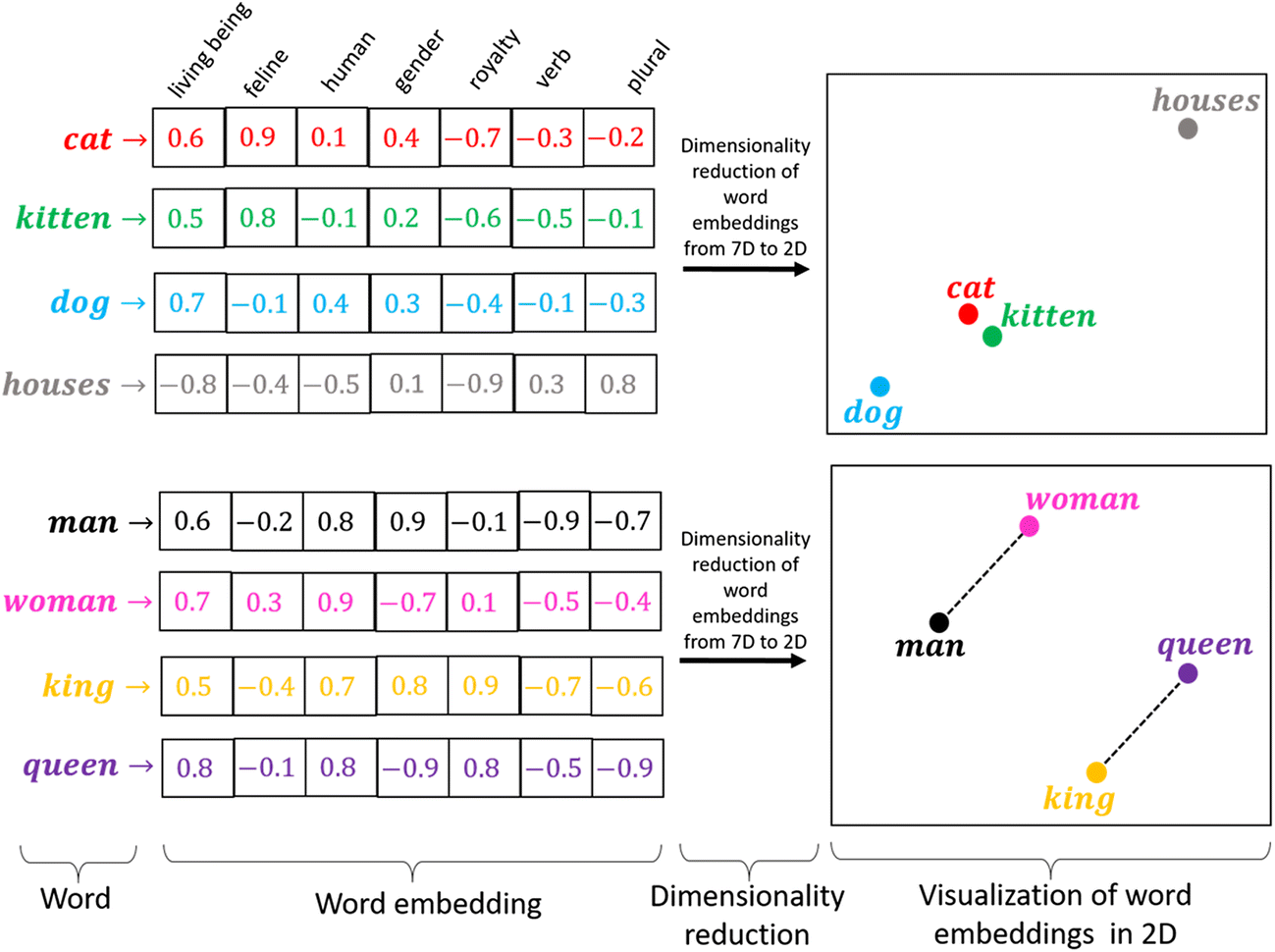
Word2Vec creates embeddings from words. To illustrate, words are encoded into one-hot vectors and fed into a hidden layer that generates hidden weights. Next, those hidden weights are then used to predict other nearby words. Words that are in similar contexts will have similar embeddings. And after that embeddings can be used to form analogies. You can understand from the example that the vector” king to man “is very similar to the one from “queen to woman”.
One drawback in Word2Vec is that single words have one vector mapping. Thus eventually all semantic uses for a word are combined into one representation. So the word “play “in “I’m going to see a play” and “I want to play” will have the same embedding, without the ability to differentiate.
3. BERT
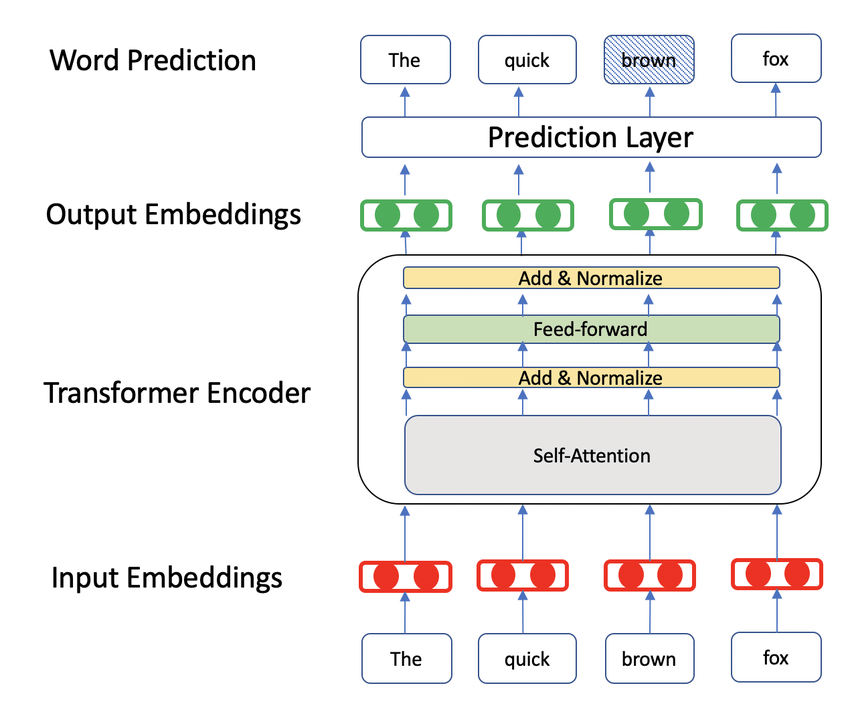
Bidirectional Encoder Representation is a pre-trained model that solves Word2Vec’s context problems. BERT follows two steps. Firstly, it is trained across a huge amount of data like Wikipedia to generate similar embeddings as Word2Vec. The second training step is performed by end users. BERT is fine-tuned for the specific use case. It has different embeddings and uses that fit the context well.
BERT is used as the go-to transformer model for generating text embeddings.
Machine Learning Embedding Operation you need to know
Any kind of production system that uses embeddings must be able to use some or all below listed Machine Learning Embedding Operations.
1. Averaging
Word2Vec generates an embedding for each word but we often need an embedding for a full sentence. In Recommender System also, we get to know items clicked on recently but maybe their embedding is not retained in days. Here, comes the role of Averaging. We can average embeddings to create higher-level embeddings. Likewise in the sentence example, we can create a sentence embedding by averaging each of the word embeddings. And in the Recommender system, we can create a user embedding by averaging the last N items they clicked.
2. Subtraction /Addition
As you have seen earlier word embeddings also encode analogies via vector differences. Adding and subtracting vectors are useful in a variety of tasks. As an example, we can find the average difference between a dress from a cheap variety and a luxury brand. Thus, we can store that data and use it whenever we want to recommend a luxury item, that’s similar to the current item that a user is looking at.
3. Nearest Neighbor
It is the most useful embedding operation. The nearest neighbor finds things that are similar to the current embedding. And Recommender systems generate a user embedding and find items that are most relevant to them. For example, in a search engine, we can find a document that’s most similar to a search query. The nearest Neighbor operation naively is O(N*K), where N is the number of items and K is the size of each embedding. However, in most cases when we need nearest neighbors, an approximation is sufficient. For instance, if we recommend five items to a user, and one is technically the sixth closest item, the user will probably not care.
Use of Artificial Neural Network in Machine Learning Embeddings
You can use different algorithms to find approximate nearest neighbors and many implementations of each of them. Let’s discuss some of the most common algorithms and implementations and see how they work at a high level.
1. Spotify’s Annoy
ANN implementation in Spotify’s Annoy creates the embeddings in a manner that turns them into a forest of trees. Each tree is built using random projections. At every intermediate node in the tree, a random hyper lane is chosen. This hyper lane divides the space into two subspaces. Moreover, this hyperlane is chosen by sampling two points from the subset and taking the hyperlane equidistant from them. The process is carried out k times to create a forest. And lookups are in order-traversal of the nearest tree. Approximate Nearest Neighbor’s approach allows the index to split. And the split is converted into multiple static files. And the index can be counterplotted in memory, and the number of trees can be adjusted to change speed and accuracy.
2. Locality Sensitive Hashing
LSH is one of the common approaches in Embedding. LSH engage a hash table and stores closeby points in their separate buckets. In order to create a marker, LSH runs numerous hashing operations which place similar points in an identical bucket. While performing so it places points with large distances in different buckets. Therefore, to get the nearest neighbor, the point in question is hashed. A lookup is carried and the closest query point is obtained. Advantages of LSH include a sub-linear run time and zero reliance on data distribution. Moreover, it has the ability to fine-tune accuracy with the existing data structure.
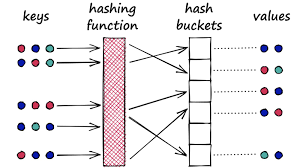
3. Facebook’s FAISS and Hierarchical Navigable Small World Graphs (HNSW)
Facebook’s implementation, FAISS uses HNSW. And HNSW generally carries out well in accuracy and recall. Also, it makes use of a hierarchical graph to generate an average path toward distinct areas. In this case, the graph has a hierarchical, transitive fabric with little average distance between intersections. And, it crosses the graph and takes out the nearest adjoining junction in each replication. Moreover, it also retains a record of the “best” neighbors found till now. HNSW has a polylogarithmic function that tells how long a program can process a given input.
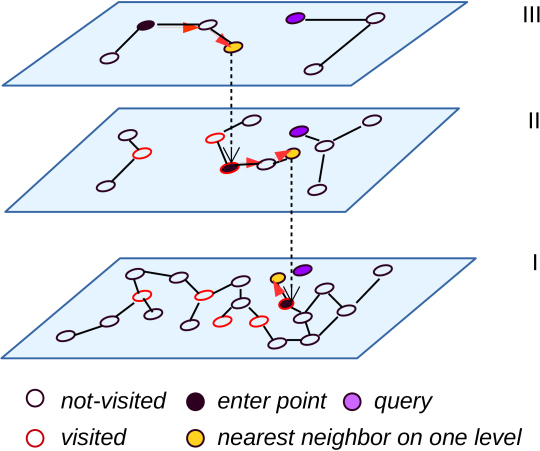
How Machine Learning Embeddings are operationalized today
Do you know what happened when embeddings moved out of labs into the real world? Actually, actual gaps came up in the existing framework capabilities. First of all, the conventional data bank and caches can’t assist functions like closest-neighbor lookups. Moreover, technical approximate closest neighbor indicators are deficit of heavy-duty storage and other characteristics essential for full production use. Conventional Machine Learning functional Systems have a shortage of styles to handle versioning, access, and training for embeddings. Modern ML systems need an embedding or a database built from the ground up around the machine learning workflow with embeddings.
Thus, utilizing Machine Learning embeddings in the production system is not easy. The most common ways used nowadays to operationalize embeddings are via Redis, Postgres, etc.
Redis
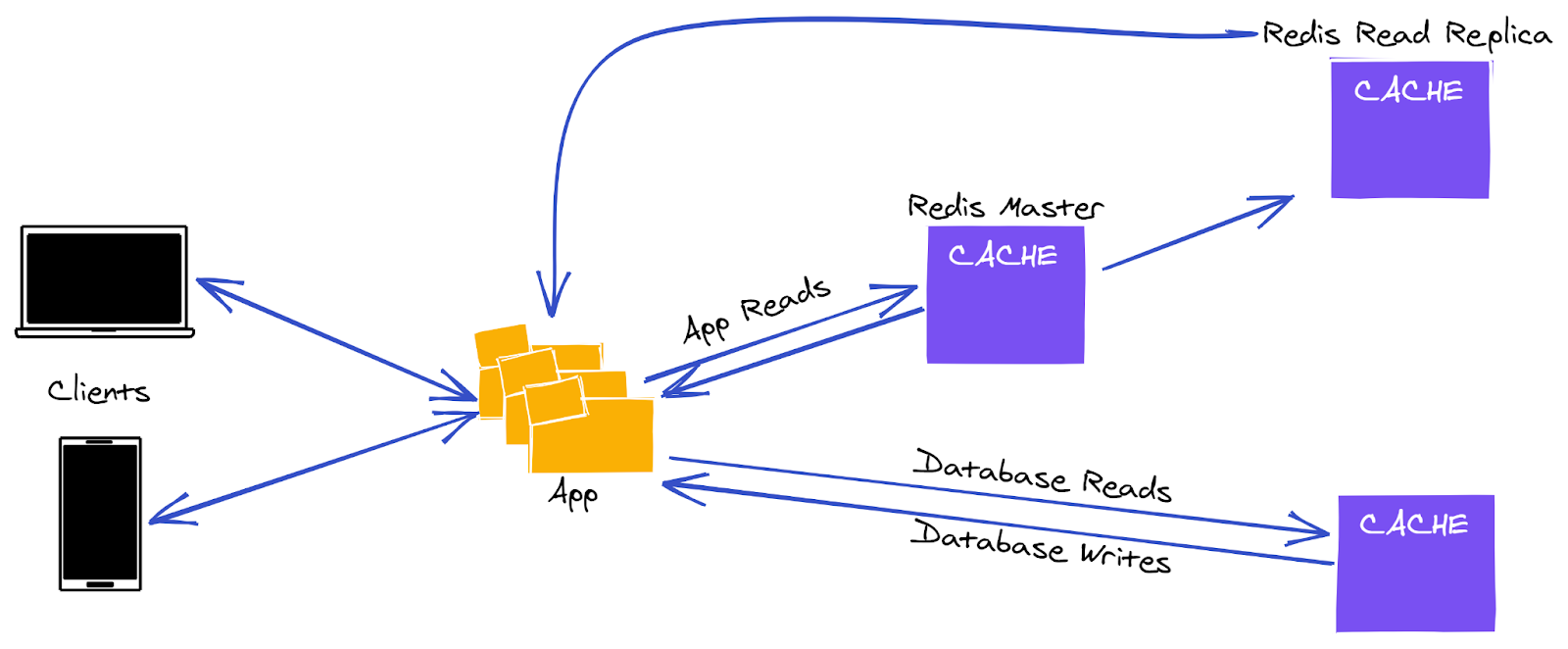
It is a super swift in-memory object reserve. Undoubtedly, it makes hoarding and obtaining embeddings super fast. But it lacks any native embedding operations. Neither it can find closest neighbor lookups nor it can add or average vectors. Moreover, it is not good for rolling back, versioning or immutability. All these put extra pressure and cost on clients.
Postgres
It is more flexible but slower than Redis. Postgres can perform some of the vector operations manually. But it does not have a consistent nearest-neighbor index. Moreover, Postgres lookup in the critical path of a model can add too much latency. Lastly, it does not handle cache embeddings well while training and thus making an extremely slow training.
The Embedding Hub
It efficiently stores machine-learning embeddings consistently. It also provides high accessibility. Especially, it permits approximate nearest-neighbor functions. And, it allows sub-indices, averaging, and partitioning. Moreover, it enables effortless access control, versioning, and rollbacks.
Companies like Pinterest have built their own in-house but there is still some gap. Startups are also spending bucks to build proprietary systems, as well as database companies, have strived to make nearest-neighbor an item on the peak.
Get ready for the Future by embracing Machine Learning Embeddings
The recent pandemic Covid-19 has further brought the relevance of the digital world. ML Algorithms are there in a variety of applications. Now every country is racing to adopt the new matrix, where the coming generation will live. Hence, Machine learning Embeddings and other next-generation models are of utmost importance. It will forever change the way how humans communicate, transact and evolve. Undoubtedly, it will create more compelling solutions for individuals and industries.
How to do more out of Embeddings by choosing Henry Harvin
Why Henry Harvin
The Institute has earned its name and fame worldwide. It ranks amongst the top 500 Global Edtech companies. It has a huge network of 300,000+ Alumni. Henry Harvin provides more than 400+ courses. Besides, it has its student base spread across 97+ Countries. The Institute is ISO 29990:2010 certified and audited by UKAF, UK cert, and MSME.
Analytical Academy of Henry Harvin offers Machine Learning Course using Python. The Certified Machine Learning Practioner(CMLP) course teaches What and How aspects of Machine Learning using popular tools such as Python and advanced-level excel. Moreover, Henry Harvin is a trusted name that got recognization among 210+corporates and 130+ colleges.
Highlights of the Machine Learning Course by Henry Harvin
- The course duration is 32 hours of classroom Training and 24 hrs live online training. Besides, the course has also 50hrs E-learning access.
- E-learning access comprises recorded Videos, Games, Projects, and Case Studies. One can join the Brushup Sessions for 1-Year and complementary modules.
- The trainers are industry experts. And their guidance enhances your skills. Moreover, they teach in a descriptive and elaborative method.
- 18,000+ distinguished alumni worldwide.
- Avail one year Gold membership of Henry Harvin Analytics Academy.
- Get various job opportunities every week and open doors to high-paying jobs.
- A guaranteed Internship is there.
Learning Benefits of Machine Learning Course by Henry Harvin
- Understand the basics of Machine learning.
- Acquire Knowledge of the Industry and best practices for Data manipulation and summarization.
- Learn about Predictive Decision Making by gaining better insights.
- Gain a full-fledged view of financial spam and medical predictions.
- Improve your precise financial decisions and accurate sales forecast.
- Learn to make macro changes in predictive models.
- Gain insight into Clustering and Decision Trees.
Henry Harvin Machine Learning Course in other cities
Contact Details: +91-9891953953 (Whatsapp available)
Conclusion
Gradually and significantly Embeddings are growing in the Machine Learning and Data science space. More and more research is going on to make embeddings useful in production systems.
In this blog, we first learned about Machine Learning Embedding, its purpose, and how it is built. Then we look at the things that can be built and how to use embedding in the Real World. In the later part, we dive into its models, operations, and about ANN usage in ML embeddings. Lastly, we delve into how embeddings are operationalized today, and what is their future scope. To sum up, we can say Embedding contains all elements to be the future of the machine learning infrastructure.
So what are your opinions on how Machine Learning Embeddings are evolving and changing the face of Technology? I would love to hear all of them in the comments box.
Recommended Reads
- Top Machine Learning Books
- Python for Data Science and Machine learning in 2022
- Top 10 Machine Learning Courses in India
- Scope of learning Artificial intelligence in India
Ans. Some of the benefits of embeddings are latency, Cost saving, Reliability, and privacy.
Ans. Machine Learning Embedding typically belongs to unsupervised learning. Moreover, it requires manually setting hyper-parameters, like a number of output dimensions.
Ans. Some embeddings can work with non-numeric data as they are designed so. For example, Word2Vector converts words into vectors.
Ans. Image embeddings are a lower-dimensional representation of the image. It can be used for many tasks like classification.
E&ICT IIT Guwahati Best Data Science Program
Ranks Amongst Top #5 Upskilling Courses of all time in 2021 by India Today
View Course
Recommended Programs
Data Science Course
With Training
The Data Science Course from Henry Harvin equips students and Data Analysts with the most essential skills needed to apply data science in any number of real-world contexts. It blends theory, computation, and application in a most easy-to-understand and practical way.
Artificial Intelligence Certification
With Training
Become a skilled AI Expert | Master the most demanding tech-dexterity | Accelerate your career with trending certification course | Develop skills in AI & ML technologies.
Certified Industry 4.0 Specialist
Certification Course
Introduced by German Government | Industry 4.0 is the revolution in Industrial Manufacturing | Powered by Robotics, Artificial Intelligence, and CPS | Suitable for Aspirants from all backgrounds
RPA using UiPath With
Training & Certification
No. 2 Ranked RPA using UI Path Course in India | Trained 6,520+ Participants | Learn to implement RPA solutions in your organization | Master RPA key concepts for designing processes and performing complex image and text automation
Certified Machine Learning
Practitioner (CMLP)
No. 1 Ranked Machine Learning Practitioner Course in India | Trained 4,535+ Participants | Get Exposure to 10+ projects
Explore Popular CategoryRecommended videos for you
Learn Data Science Full Course
Python for Data Science Full Course
What Is Artificial Intelligence ?
Demo Video For Artificial intelligence
Introduction | Industry 4.0 Full Course
Introduction | Industry 4.0 Full Course
Demo Session for RPA using UiPath Course
Feasibility Assessment | Best RPA Using Ui Path Online Course









.webp)
